
编译设计文档
姓名:马泽远
学号:20373793
一. 参考编译器介绍
Pcode代码生成部分(包括Pcode代码执行)部分参考了《自己动手写编译器》。
其余部分参考了往年的编译指导文档,包括一些往届学长的编译器设计架构
二. 编译器总体设计
总体结构
我的编译器总体结构按照编译的顺序,即词法分析、语法分析、语义分析、代码生成,分为四个部分。
-
有几个类用来定义基本的一些需要用到的变量,比如**
TokenWord类对应着单词类**,其属性包括单词内容,类别码,所在行数。类似的,还有**Symbol类对应着符号类**,Expressions类对应着表达式类,用于表示一个具有多个表达式的大表达式,以及**SymbolTable类对应着符号表类**,Func类对应着函数类,还有**Error类**。 -
另外的几个类,则是分别对应着相应的几个编译器执行过程,
LexicalAanlysis类对应词法分析,GrammarAanlysis类综合了语法分析,语义分析、错误处理,以及生成中间代码(Pcode码) -
而对于
Pcode的定义,执行则是单独设置了一个文件包**PcodeGeneration,其中包含对Pcode的Function、Execute,retinfo,variety**以及其本身。 -
Compiler类对应着编译器的总入口。在其中,依次调用**LexicalAanlysis,GrammarAanlysis,PcodeExecutor类,即可完成词法分析到语法分析到语义分析到代码生成的整个过程,形成了类似一个单向链**,每一个部分都是一个单独的模块。
文件组织
src
│ Compiler.java #入口程序
│ Error.java #错误类
│ Expressions.java #表达式类
│ Func.java #函数类
│ GrammarAnalysis.java #语法分析、错误处理、代码生成类
│ lexicalAnalysis.java #词法分析类
│ Symbol.java #符号类
│ SymbolTable.java #符号表类
│ TokenWord.java #单词类
└─PcodeGeneration
Function.java #Pcode中的函数类
LabelCreator.java #标签制造
Pcode.java #Pcode代码类
PcodeExecutor.java #Pcode运行虚拟机类
PcodeKey.java #枚举Pcode中的关键词
RetInfo.java #返回信息类
Variety.java #变量类
类图
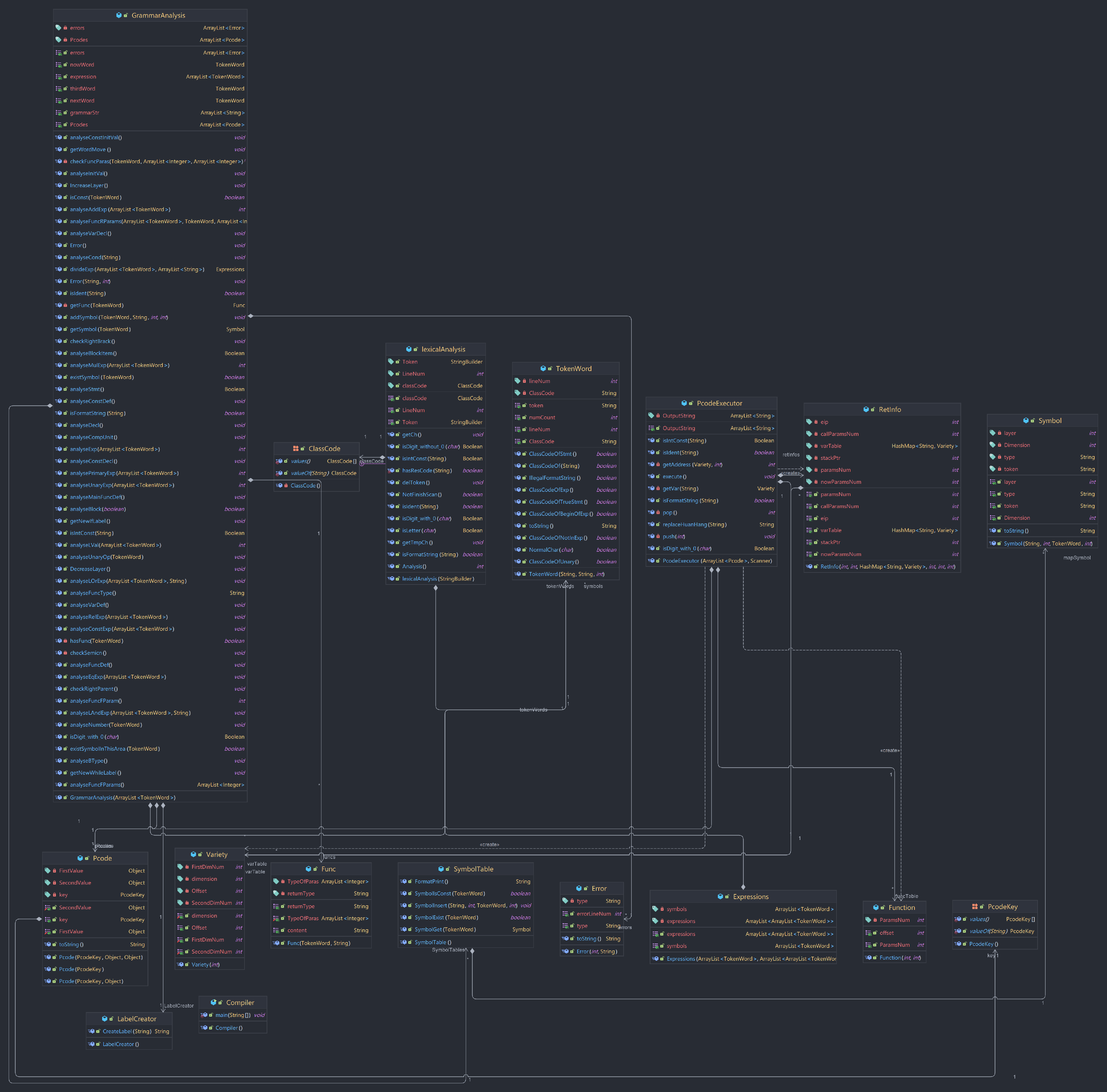
三. 词法分析设计
1 总述
词法分析的总任务是从源程序中识别出单词,记录单词类别和单词值。在词法分析的设计中给了一张表,其中有三项是加粗说明的,分别是 变量名(Ident),整常数(IntConst) 和 格式字符串(FormatString) 而剩下都可以认为是 特殊字符。
词法分析的作业本质上就是把文件转换成一个个的词,在之后的文章中我们称之为 TokenWord。然后再把分出来的**TokenWord**进行类别的判断,最后输出。
2 实现
2.1 文件读写
InputStreamReader Reader = new InputStreamReader(new FileInputStream("testfile.txt"), "UTF-8");
BufferedReader bufferedReader = new BufferedReader(Reader);
OutputStreamWriter Writer = new OutputStreamWriter(new FileOutputStream("output.txt"), "UTF-8");
BufferedWriter bufferedWriter = new BufferedWriter(Writer);
利用bufferedReader逐行读入文件,注意需要手动加入换行符(最后添加的一个要删掉)
while ((line = bufferedReader.readLine()) != null) {
str.append(line).append("\n");
}
str.delete(str.length() - 1, str.length());
将lexicalAnalysis中分析得到的tokenWords写出
for(TokenWord tokenWord :lexicalAnalysis.tokenWords)
{
bufferedWriter.write(tokenWord.getClassCode()+" "+ tokenWord.getToken()+"\n");
}
2.2 词法分析过程
准备工作
标识符定义采用enum枚举ClassCode的方法
public static enum ClassCode {
IDENFR,
INTCON,
STRCON,
......
同时采用HashMap构造一些特定标识符的对应关系
public static HashMap<String, String> ResCode = new HashMap<String, String>();
public static boolean hasResCode(String token) {
return ResCode.containsKey(token);
}
static {
ResCode.put("main", "MAINTK");
ResCode.put("const", "CONSTTK");
......
具体分析
总体采取逐个字符读入的方式,同时一些特定字符采取预读取来判断。
逐个字符读入
public void getCh() {
ch = allFile.charAt(cursor);
cursor++;
}
跳过换行、空格、\t、\r
while (ch == '\n' || ch == ' ' || ch == '\t' || ch == '\r') {
if (ch == '\n' || ch == '\r') {
LineNum++;
}
if (cursor <= allFile.length() - 1) {
getCh();
}
}
标识符
字母或者下划线开头,先从ResCode看是否是保留字,否则按照IDNEFR处理
if (isLetter(ch) || ch == '_') {
while (isLetter(ch) || isDigit_with_0(ch) || ch == '_') {
Token.append(ch);
if (cursor <= allFile.length() - 1) {
getCh();
}
}
//reback
if (cursor > 0) {
cursor--;
}
if (hasResCode(Token.toString())) {
classCode = ClassCode.valueOf(ResCode.get(Token.toString()));
tokenWords.add(new TokenWord(classCode.toString(),Token.toString(),LineNum));
} else {
classCode = ClassCode.IDENFR;
tokenWords.add(new TokenWord(classCode.toString(),Token.toString(),LineNum));
}
INTCON
先判断是否是0
if (isDigit_with_0(ch)) {
if (ch == '0') {
Token.append(ch);
} else {
while (isDigit_with_0(ch)) {
Token.append(ch);
getCh();
}
if (cursor > 0) {
cursor--;
}
classCode = ClassCode.INTCON;
tokenWords.add(new TokenWord(classCode.toString(),Token.toString(),LineNum));
}
}
字符串
遇到"开始,直到遇到下一个"
if (ch == '"') {
Token.append(ch);
if (cursor <= allFile.length() - 1) {
getCh();
}
while (cursor <= allFile.length() - 1 && ch != '"') {
Token.append(ch);
getCh();
}
Token.append(ch);
classCode = ClassCode.STRCON;
tokenWords.add(new TokenWord(classCode.toString(),Token.toString(),LineNum));
}
单个字符或者必须两个字符的TokenWord
比如[,],+,&&等,直接读就可以
可能是单个也可能两个字符的TokenWord
比如>=,!=之类的
采用预读
if (ch == '=') {
Token.append(ch);
if (cursor <= allFile.length() - 1) {
getCh();
if (ch == '=') {
Token.append(ch);
classCode = ClassCode.EQL;
tokenWords.add(new TokenWord(classCode.toString(),Token.toString(),LineNum));
} else {
classCode = ClassCode.ASSIGN;
if (cursor > 0) {
cursor--;
}
tokenWords.add(new TokenWord(classCode.toString(),Token.toString(),LineNum));
}
} else {
classCode = ClassCode.ASSIGN;
tokenWords.add(new TokenWord(classCode.toString(),Token.toString(),LineNum));
}
}
注释
遇到/的情况下,采用预读
//:并且一直读到遇到换行符
/*:利用BackStr = allFile.substring(cursor);提取出第一个*后面的字符串BackStr;然后判断其中有没有*/,若是没有,就将后面的内容全部注释掉,若是有就将cursor移动到其后面,但是注意要遇到换行符时加行数。
否则/:直接按照DIV输出
if (ch == '/') {
Token.append(ch);
if (cursor <= allFile.length() - 1) {
getCh();
if (ch == '/') {
if (cursor <= allFile.length() - 1) {
getCh();
}
while (ch != '\n') {
if (cursor <= allFile.length() - 1)
getCh();
else {
noteFlag = true;
break;
}
}
if (!noteFlag) {
LineNum++;
}
noteFlag = false;
return -2;
} else if (ch == '*') {
String BackStr;
boolean flagnote;
int cursortmp = cursor;
BackStr = allFile.substring(cursor);
if (!BackStr.contains("*/")) {
cursor = allFile.length();
return -2;
} else {
cursor = cursor + BackStr.indexOf("*/") + 2;
int originLength = allFile.substring(cursortmp, cursor).length();
int replaceLength = allFile.substring(cursortmp, cursor).replace("\n", "").length();
LineNum += originLength - replaceLength;
return -2;
}
} else {
classCode = ClassCode.DIV;
if (cursor > 0) {
cursor--;
}
tokenWords.add(new TokenWord(classCode.toString(),Token.toString(),LineNum));
}
} else {
classCode = ClassCode.DIV;
tokenWords.add(new TokenWord(classCode.toString(),Token.toString(),LineNum));
}
}
四. 语法分析设计
1 总述
在语法分析阶段,根据词法分析程序识别出的Token单词,根据SysY语法规则识别出各种语法元素。采用递归下降法对语法中定义的语法成分进行分析。注意要消除左递归,以及面对可能的回溯问题进行预读。
从**CompUnit**开始逐层往下进行分析。
2 具体实现
-
设置
getWordMove(),getNowWord(),getNextWord(),getThirdWord()工具函数用于读入tokenWord,同时设置GrammarString,curTokenWord等全局变量,用于存储获得的语法分析成分,以及当前所读到的tokenWord。 -
对于普通的语法成分,我逐个读入
tokenWord,然后对其进行常规的分析。对于表达式
Expression,我首先扫描出整个的Expression,然后对于具有左递归性的语法规则,再依据特定的分隔符,对整个大的Expression进行分割成若干个较短的Expression,然后依次调用对应子表达式的分析方法,进行递归下降法进行分析。 -
构建了一个新的
Expressions类,用于存放分割出的子表达式,其中记录有分隔符,分割出的子表达式public class Expressions { private ArrayList<TokenWord> symbols; private ArrayList<ArrayList<TokenWord>> expressions; public ArrayList<ArrayList<TokenWord>> getExpressions() { return expressions; } public ArrayList<TokenWord> getSymbols() { return symbols; } public Expressions(ArrayList<TokenWord> symbols, ArrayList<ArrayList<TokenWord>> expressions) { this.symbols = symbols; this.expressions = expressions; } }
2.1 获取表达式–getExpression
通过一些特定的判断条件,结合当前字符以及前一个字符的值进行判断,以及是否位于函数的判断等,进行表达式的获取(后续改写的时候比较繁琐)
public ArrayList<TokenWord> getExpression() {
TokenWord preWord = null;
TokenWord word = getNowWord();
ArrayList<TokenWord> exp = new ArrayList<>();
boolean inFunc = false;
int FuncFlag = 0;
int FlagSmall = 0;
int FlagBig = 0;
while (true) {
if (word.ClassCodeOf("SEMICN") || word.ClassCodeOf("ASSIGN") || word.ClassCodeOf("RBRACE") || word.ClassCodeOfTrueStmt()) {
break;
}
//不在函数声明或者引用内,且遇到','
if (word.ClassCodeOf("COMMA") && !inFunc) {
break;
}
//单词不在表达式内
if (preWord != null) {
if ((preWord.ClassCodeOf("INTCON") || preWord.ClassCodeOf("IDENFR")) && (word.ClassCodeOf("INTCON") || word.ClassCodeOf("IDENFR"))) {
break;
}
if ((preWord.ClassCodeOf("RPARENT") || preWord.ClassCodeOf("RBRACK")) && (word.ClassCodeOf("INTCON") || word.ClassCodeOf("IDENFR"))) {
break;
}
if (FlagSmall == 0 && FlagBig == 0) {
if (preWord.ClassCodeOf("INTCON") && word.ClassCodeOf("LBRACK")) {
break;
}
if (preWord.ClassCodeOf("INTCON") && word.ClassCodeOf("LBRACE")) {
break;
}
}
}
if (word.ClassCodeOfNotInExp()) {
break;
}
//在函数内部
if (word.ClassCodeOf("IDENFR")) {
if (getNextWord().ClassCodeOf("LPARENT")) {
inFunc = true;
}
}
//(),[]识别
if (word.ClassCodeOf("LPARENT")) {
FlagSmall++;
if (inFunc) {
FuncFlag++;
}
}
if (word.ClassCodeOf("RPARENT")) {
FlagSmall--;
if (inFunc) {
FuncFlag--;
if (FuncFlag == 0) {
inFunc = false;
}
}
}
switch (word.getClassCode()) {
case "LBRACK":
FlagBig++;
break;
case "RBRACK":
FlagBig--;
break;
}
if (FlagSmall < 0) {
break;
}
if (FlagBig < 0) {
break;
}
curTokenWord = tokenWords.get(cursor);
cursor++;
exp.add(curTokenWord);
preWord = word;
word = getNowWord();
}
return exp;
}
2.2 递归下降
对于一条语法推导规则,若其推导出的式子中含有$V_{N}$,那么考虑采用递归下降分析法
在我的实现中,我每读一个tokenWord,检查它属于哪一个$V_{N}$,然后进入下一个相应的分析函数。
例如CompUnit:
CompUnit → {Decl} {FuncDef} MainFuncDef // 1.是否存在Decl 2.是否存在 FuncDef
具体实现:
public void analyseCompUnit() {
TokenWord word = getNowWord();
while (word.ClassCodeOf("CONSTTK") || (word.ClassCodeOf("INTTK") && getNextWord().ClassCodeOf("IDENFR") && !getThirdWord().ClassCodeOf("LPARENT"))) {
analyseDecl();
word = getNowWord();
}
while (word.ClassCodeOf("VOIDTK") || ((word.ClassCodeOf("INTTK") && !getNextWord().ClassCodeOf("MAINTK")))) {
analyseFuncDef();
word = getNowWord();
}
if (word.ClassCodeOf("INTTK") && getNextWord().ClassCodeOf("MAINTK")) {
analyseMainFuncDef();
} else {
Error();
}
GrammarString.add("<CompUnit>");
}
又比如Stmt
语句 Stmt → LVal '=' Exp ';' // 每种类型的语句都要覆盖
| [Exp] ';' //有无Exp两种情况
| Block
| 'if' '(' Cond ')' Stmt [ 'else' Stmt ] // 1.有else 2.无else
| 'while' '(' Cond ')' Stmt
| 'break' ';' | 'continue' ';'
| 'return' [Exp] ';' // 1.有Exp 2.无Exp
| LVal '=' 'getint''('')'';'
| 'printf''('FormatString{','Exp}')'';' // 1.有Exp 2.无Exp
具体实现:
public void analyseStmt() {
TokenWord word = getNowWord();
if (word.ClassCodeOf("IDENFR")) {
ArrayList<TokenWord> exp = getExpression();
if (!getNowWord().ClassCodeOf("SEMICN")) {
analyseLVal(exp);
getWordMove();//=
if (getNowWord().ClassCodeOf("GETINTTK")) {
getWordMove();//getint
getWordMove();//(
getWordMove();//)
getWordMove();//;
} else {
analyseExp(getExpression());//
getWordMove(); //;
}
} else {
analyseExp(exp);
getWordMove();//;
}
} else if (word.ClassCodeOfBeginOfExp()) {
analyseExp(getExpression());
getWordMove();//;
} else if (word.ClassCodeOf("LBRACE")) {
analyseBlock();
} else if (word.ClassCodeOf("IFTK")) {
getWordMove();//if
getWordMove();//(
analyseCond();
getWordMove();//)
analyseStmt();
word = getNowWord();
if (word.ClassCodeOf("ELSETK")) {
getWordMove(); //else
analyseStmt();
}
} else if (word.ClassCodeOf("WHILETK")) {
getWordMove();//while
getWordMove();//(
analyseCond();
getWordMove();//)
analyseStmt();
} else if (word.ClassCodeOf("BREAKTK")) {
getWordMove();//break
getWordMove();//;
} else if (word.ClassCodeOf("CONTINUETK")) {
getWordMove();//continue
getWordMove();//;
} else if (word.ClassCodeOf("RETURNTK")) {
getWordMove();//return
word = getNowWord();
if (word.ClassCodeOfBeginOfExp()) {
analyseExp(getExpression());
}
getWordMove();//;
} else if (word.ClassCodeOf("PRINTFTK")) {
getWordMove();//printf
getWordMove();//(
getWordMove();//STRCON
word = getNowWord();
while (word.ClassCodeOf("COMMA")) {
getWordMove();//,
analyseExp(getExpression());
word = getNowWord();
}
getWordMove();//)
getWordMove();//;
} else if (word.ClassCodeOf("SEMICN")) {
getWordMove();//;
}
GrammarString.add("<Stmt>");
}
在以上的分析过程中,需要注意的是
- 一些语法成分内部分析过程的细节性注意(括号匹配等问题)
- 面对$V_{N}$,需要
getNowWord()预读,但是不能直接加入GrammarString中,需要进一步判断属于哪个$V_{N}$
2.3 左递归消除
采用转换为BNF范式的方法消除左递归
例如加减表达式
AddExp → MulExp | AddExp ('+' | '−') MulExp // 1.MulExp 2.+ 需覆盖 3.- 需覆盖
改写为
AddExp → MulExp ('+' | '−') MulExp ('+' | '−') MulExp ...
改写完以后,构造**divideExp()**方法,将整个大的表达式进行分割,再依次调用子程序进行分析
private Expressions (divideExp(ArrayList<TokenWord> exp, ArrayList<String> symbol):
-
输入:表达式
exp,分隔符列表返回:分割出的子表达式,分割符号列表 ————
return new Expressions(symbols, exps)public Expressions divideExp(ArrayList<TokenWord> exp, ArrayList<String> symbol) { ArrayList<ArrayList<TokenWord>> exps = new ArrayList<>(); ArrayList<TokenWord> tmpExp = new ArrayList<>(); ArrayList<TokenWord> symbols = new ArrayList<>(); boolean unaryFlag = false; int FlagSmall = 0; int FlagBig = 0; for (TokenWord word : exp) { switch (word.getClassCode()) { case "LPARENT": FlagSmall++; break; case "RPARENT": FlagSmall--; break; case "LBRACK": FlagBig++; break; case "RBRACK": FlagBig--; break; } //遇到指定分隔符,并且(),[]得到匹配 if (symbol.contains(word.getClassCode()) && FlagSmall == 0 && FlagBig == 0) { //如果分隔符是单目运算符 if (word.ClassCodeOfUnary()) { //如果上一个word不是识别符,),],int常数,那么不在此处分割,仅将当前word加入exp if (!unaryFlag) { tmpExp.add(word); continue; } } //如果上一个word不是识别符,),],int常数,向exps中加入当前表达式,并且重置表达式,向分隔符列表中加入当前word exps.add(tmpExp); symbols.add(word); tmpExp = new ArrayList<>(); } else { tmpExp.add(word); } unaryFlag = word.ClassCodeOf("IDENFR") || word.ClassCodeOf("RPARENT") || word.ClassCodeOf("INTCON") || word.ClassCodeOf("RBRACK"); } exps.add(tmpExp); return new Expressions(symbols, exps); }
最终例如加减表达式,分析代码如下
public void analyseAddExp(ArrayList<TokenWord> exp) {
Expressions exps = divideExp(exp, new ArrayList<>(Arrays.asList("PLUS", "MINU")));
int j = 0;
for (ArrayList<TokenWord> tmpExp : exps.getExpressions()) {
analyseMulExp(tmpExp);
GrammarString.add("<AddExp>");
if (j < exps.getSymbols().size()) {
GrammarString.add(exps.getSymbols().get(j++).toString());
}
}
}
五. 错误处理设计
1 总体设计
-
新定义类
- 定义
Error类,存放错误的类型,所在行数 - 定义
Symbol类,type是指符号的类型,例如const,var,para。Dimension是一个整数,指出了符号的维数。如果为0,则符号为int。如果为1,则符号为int[];如果为2,则符号为int[][]…。token是指Symbol的内容。layer就是这个符号所在的层级。
public Symbol(String type, int Dimension, TokenWord tokenWord, int layer) { this.type = type; this.Dimension = Dimension; this.token = tokenWord.getToken(); this.layer = layer; }-
定义
SymbolTable类来存放符号表,在其中用HashMap<String, Symbol> mapSymbol来存放符号,同时在其中定义了一些基础的方法 -
定义
Func类,分别记录函数名、函数返回类型(void,int)、以及函数的参数类型用
ArrayList<Integer> TypeOfParas来记录函数的参数类型,0、1、2分别代表着int,int[],int[][]Type Example Integer Void (函数返回值为空) -1 Int a 0 Int[] a[] 1 Int[] [] a[] [3] 2
- 定义
-
在
GrammarAnalysis类中,我定义了如下几个新的变量private final ArrayList<Error> errors = new ArrayList<>(); //函数名Hashmap private final HashMap<String, Func> funcs = new HashMap<>(); //层级layer对应符号表,每当进入一个新层级,就将layer++,新构造一个SymbolTables private final HashMap<Integer, SymbolTable> SymbolTables = new HashMap<>(); private int layer = -1; private boolean ReturnFlag = false;//表示当前函数是否需要返回。 private int IndexWhile = 0; //表示当前代码块是否在while中。 -
注意:
在
AnalyseBlock中对于一个自定义函数,与函数的参数是同一个Layer的(否则无法判断函数内部重复定义函数参数等错误)而对于main函数,进入到Block的时候,Layer要加1(main函数内部可以重复定义全局变量)private boolean analyseBlock(boolean fromFunc) { ... if (!fromFunc) { IncreaseLayer(); } ... if (!fromFunc) { DecreaseLayer(); } }
2 具体分析 Errors
a
检查格式就好
public boolean IllegalFormatString() {
int i = 1;
while (i <= content.length() - 2) {
if (NormalChar(content.charAt(i))) {
if (content.charAt(i) == '\\') {
if (content.charAt(i + 1) != 'n') {
return true;
}
}
i++;
} else {
if (content.charAt(i) == '%' && content.charAt(i + 1) == 'd') {
i++;
} else {
return true;
}
}
}
return false;
}
b c
b: 对于变量、函数参数来说,每次我得到一个Ident识别符,检查是否有相同的符号被定义在同一层级。对于函数来说,直接查看funcs.containsKey(curTokenWord.getToken())。
//判断当前区块是否有当前符号 b
public boolean existSymbolInThisArea(TokenWord tokenWord) {
return SymbolTables.get(layer).SymbolExist(tokenWord);
}
c: 检查所有层级的符号表,此函数符号是否已定义。函数直接查看funcs
private boolean hasSymbol(Word word) {
for (Symbols s : symbols.values()) {
if (s.hasSymbol(word)) {
return true;
}
}
return false;
}
d e
首先,为了获取每一个函数参数(可能为表达式)的真实维数,我在语法分析器的递归下降过程中,按照Exp->Add->Mul->Unary->Primary/Func->Lval/Exp这个路径,每个分析函数分别返回维数(调用下一层获得),直到Lval。
public int analyseExp(ArrayList<TokenWord> exp) {
int Dimension = analyseAddExp(exp);
GrammarString.add("<Exp>");
return Dimension;
}
在Lval中,结束递归调用,返回最终结果
注意
例如a[3][5],lval对应a[3],那么实际数组维数是1 考虑到a[b[3]]
private int analyseLVal(ArrayList<Word> exp) {
TokenWord Ident = exp.get(0);
if (!existSymbol(Ident)) {
Error("c", Ident.getLineNum());
}
GrammarString.add(Ident.toString());//Ident
//若是数组
if (exp.size() > 1) {
ArrayList<TokenWord> tmpExp = new ArrayList<>();
int flag = 0;
//逐个扫描
for (int i = 1; i < exp.size(); i++) {
TokenWord word = exp.get(i);
if (word.ClassCodeOf("LBRACK")) {
if (flag == 0) {
Dimension++; //a[]这种,而不是a[[]](不能加维数)
}
flag++;
if (flag == 1) {
GrammarString.add(word.toString());
tmpExp = new ArrayList<>();
} else {
tmpExp.add(word);
}
} else if (word.ClassCodeOf("RBRACK")) {
flag--;
if (flag == 0) {
analyseExp(tmpExp);
GrammarString.add(word.toString());
} else {
tmpExp.add(word);
}
} else {
tmpExp.add(word);
}
}
if (flag > 0) {
analyseExp(tmpExp);
Error("k", exp.get(exp.size() - 1).getLineNum()); // not sure
}
}
GrammarString.add("<LVal>");
//如上注意
if (existSymbol(Ident)) {
return getSymbol(Ident).getDimension() - Dimension;
} else {
return 0;
}
}
定义checkFuncParas函数来进行参数数目,参数维数判断,在分析analyseFuncRParams时进行调用
//检查函数参数匹配问题
private void checkFuncParas(TokenWord funcName, ArrayList<Integer> standardTypeOfParas, ArrayList<Integer> nowTypeOfParas) {
if (standardTypeOfParas.size() != nowTypeOfParas.size()) {
Error("d", funcName.getLineNum());
} else {
for (int i = 0; i < standardTypeOfParas.size(); i++) {
if (!Objects.equals(standardTypeOfParas.get(i), nowTypeOfParas.get(i))) {
Error("e", funcName.getLineNum());
}
}
}
}
public void analyseFuncRParams(ArrayList<TokenWord> exp, TokenWord Ident, ArrayList<Integer> TypeOfParas) {
ArrayList<Integer> nowParas = new ArrayList<>();
Expressions exps = divideExp(exp, new ArrayList<>(Collections.singletonList("COMMA")));
int j = 0;
for (ArrayList<TokenWord> tmpExp : exps.getExpressions()) {
int Dimension = analyseExp(tmpExp);
nowParas.add(Dimension);
if (j < exps.getSymbols().size()) {
GrammarString.add(exps.getSymbols().get(j++).toString());
}
}
if (TypeOfParas != null) {
checkFuncParas(Ident, TypeOfParas, nowParas);
}
GrammarString.add("<FuncRParams>");
}
然后在analyseFuncRParams时,如果遇到了函数调用那么进行判断
if (exp.size() > 3) {
//实参列表有东西
analyseFuncRParams(new ArrayList<>(exp.subList(2, exp.size() - 1)), Ident, TypeOfParas);
} else {
//实参列表没东西
if (TypeOfParas != null) {
if (TypeOfParas.size() != 0) {
Error("d", Ident.getLineNum());
}
}
}
f g
如果当前函数需要返回,会有一个全局变量 ReturnFlag来显示,初始化为false。其在analyseFuncDef()以及analyseMainFuncDef()中,得到赋值。
-
对于f
在分析
Stmt中的RETURNTK时候,若ReturnFlag为false,那么就产生**f**错误 -
对于g
定义了
hasReturn变量,其在analyseBlock→BlockItem/Stmt→Stmt这条路径上进行调用传递,并作为返回值返回然后在
analyseFuncDef()以及analyseMainFuncDef()中对ReturnFlag && !hasReturn进行判断,若是真则产生**g**错误
h
判断是否为常数即可
if (isConst(word)) {
Error("h", word.getLineNum());
}
i j k
定义函数来检查,以)为例
//检查右小括号
public void checkRightParent() {
if (getNowWord().getClassCode().equals("RPARENT")) {
getWordMove();
} else {
Error("j", curTokenWord.getLineNum());
}
}
l
分析Stmt遇到PRINTFTK时,判断一下printf里面逗号的数量和STRCON中的要求输出数是否一致即可
m
如果代码块在While循环中,则有一个全局变量WhileFlag表示,其值不为0。在遇到break或是continue的时候判断一下即可
六. 生成代码设计
在这一部分中,我选择生成pcode代码。我设计了一种基于逆波兰表达式堆栈和符号表的虚拟Pcode代码,在进行语法分析的过程中,随之生成Pcode代码。 同时,我设计了执行它们的虚拟机。Pcode虚拟机是用于运行Pcode命令的虚构机器。 它由一个代码区(pcodes)、一个指令指针(EIP)、一个main函数指针(mainAddress)、一个堆栈(存放各种数值)、存放返回信息的数组、一个变量表var_table,一个函数表func_table和一个标签表label_table组成。
在接下来的文章中,我将首先介绍如何生成pcode,然后介绍pcode如何执行。
编码前设计
如何生成Pcode
新增的类
在PcodeGeneration包中,我新增了
-
Function类————记录函数声明在Pcodes代码中的位置以及其参数数量public Function(int index, int argsNum) { this.StackOffset = index; this.ParamsNum = argsNum; } -
LabelCreator类————用于产生标签 -
Variety类————记录变量在栈上的位置,维度数,各维数的数量 -
RetInfo类————记录函数的返回地址(调用函数指令的下一条指令的EIP),调用函数前栈上的末尾位置(stack.size() - 1),虚拟机中当前的变量表(var_table),函数的参数数量,函数所需调用的参数数量,目前已有的参数数量public RetInfo(int eip, int stackPtr, HashMap<String, Variety> varTable, int paramsNum, int callArgsNum, int nowArgsNum) { this.eip = eip; this.stackPtr = stackPtr; this.varTable = varTable; this.paramsNum = paramsNum; this.callParamsNum = callArgsNum; this.nowParamsNum = nowArgsNum; } -
Pcode类————记录一个Pcode指令的名称key,FirstValue,LastValue(如有),同时规定了Pcode的规范化输出(label,func,call,print进行特殊考虑)@Override public String toString() { String first = ""; String second = ""; if (key.equals(PcodeKey.label)) { return FirstValue.toString() + ": "; } if (key.equals(PcodeKey.func)) { return "FUNC @" + FirstValue.toString() + ":"; } if (key.equals(PcodeKey.call)) { return "$" + FirstValue.toString(); } if (key.equals(PcodeKey.print)) { return key + " " + FirstValue; } if (FirstValue == null) { first = ""; } else { first = FirstValue.toString(); } if (SecondValue == null) { second = ""; } else { second = ", " + SecondValue.toString(); } return key + " " + first + second; } -
PcodeKey枚举类,存放Pcode的基本指令名称,后面会详细介绍
变量声明
如何区分不同的变量
根据唯一的作用域号区分不同作用域的变量,如:CurLayerId + "_" + Ident.getToken()。在这种情况下,除了递归函数调用以外,代码中不会多次重复出现该变量,可以通过将varTable到堆栈来解决。
不区分const和var。
- 非数组变量:新建一个变量
var并让它指向堆栈顶部。如果它有初始化,push初始化的值进入堆栈(如果int x=q这种初始化,那么需要push q,然后再getvalue)。如果未初始化,则添加一个defaultvalue命令来将变量的默认初始值(我将其推入0)推送到堆栈。 - 数组变量:新建一个变量
var并让它指向堆栈顶部。然后push其各维的维数,然后用dimarrayvar命令表示他是数组,如果它有初始化,依次push初始化的值进入堆栈。如果未初始化,则添加一个defaultvalue命令来将变量的默认初始值(我将其推入0)推送到堆栈。 - 如果是
getint,那么加入getint
eg:int x[1][3];
var 1_x
push 1
push 3
dimarrayvar 1_x, 2
defaultvalue 1_x, 2
赋值语句
首先push待赋值的变量(若是数组,还需要push偏移量),然后利用getaddress计算并将变量的地址推送到堆栈顶部。然后分析赋值语句右侧的表达式,对于数值,直接push,对于表达式,利用getvalue获取表达式的值。(若是算术运算表达式,就先执行)在此之后,堆栈中有两个数字,即地址和值。利用pop将该值分配给该地址。
变量取值
例如要取得x[0][2]的值
push 2_x push 0 push 2 getvalue 2_x, 0
函数定义
直接Pcodes.add(new Pcode(PcodeKey.func, curTokenWord.getToken()));(mainfunc特殊定义)
函数形参
fparam+名字+维数
注意:若是数组,需要先push进去各维数量(二维形参,只需要push第二维数量)
函数调用
实参类型
-
数值:先
push函数实参,再rparam+函数实参名字+维数,再call相应函数名 -
变量:先
push变量名-
若是数组,就
getaddress加维数 -
若是普通变量,就
getvalue+维数;若是a[1][3]这种,就先push进去1,3,再getvalue剩下的操作同上
-
函数返回
ret 0代表无返回值
ret 1代表有返回值,在ret之前会有push(由分析表达式产生)之类的,代表返回指的具体数值
打印语句
Pcodes.add(new Pcode(PcodeKey.print, STRCON.getToken(), OutputNum));
注意:打印变量,则按照老套路,先push变量,再getvalue例如printf("%d",x);,则是push 2_x , getvalue 2_x, 0 print "%d"
条件跳转控制语句
首先,我定义了三个ArrayList,分别存放着对应标签的HashMap
private ArrayList<HashMap<String, String>> If_Labels = new ArrayList<>();
private ArrayList<HashMap<String, String>> While_Labels = new ArrayList<>();
private ArrayList<HashMap<Integer, String>> Cond_Labels = new ArrayList<>();
每当遇到IFTK或其他判断语句时,生成相应标签
public void getNewIfLabel() {
HashMap<String, String> tmpIfLabel = new HashMap<>();
tmpIfLabel.put("if", LabelCreator.CreateLabel("if"));
tmpIfLabel.put("else", LabelCreator.CreateLabel("else"));
tmpIfLabel.put("endif", LabelCreator.CreateLabel("endif"));
tmpIfLabel.put("ifblock", LabelCreator.CreateLabel("ifblock"));
If_Labels.add(tmpIfLabel);
}
以if为例子
if (word.ClassCodeOf("IFTK")) {
getNewIfLabel();
Pcodes.add(new Pcode(PcodeKey.label, If_Labels.get(If_Labels.size() - 1).get("if")));
getWordMove();//if
getWordMove();//(
analyseCond("if");
checkRightParent();
Pcodes.add(new Pcode(PcodeKey.jz, If_Labels.get(If_Labels.size() - 1).get("else")));
Pcodes.add(new Pcode(PcodeKey.label, If_Labels.get(If_Labels.size() - 1).get("ifblock")));
analyseStmt();
word = getNowWord();
Pcodes.add(new Pcode(PcodeKey.jmp, If_Labels.get(If_Labels.size() - 1).get("endif")));
Pcodes.add(new Pcode(PcodeKey.label, If_Labels.get(If_Labels.size() - 1).get("else")));
if (word.ClassCodeOf("ELSETK")) {
getWordMove(); //else
analyseStmt();
}
Pcodes.add(new Pcode(PcodeKey.label, If_Labels.get(If_Labels.size() - 1).get("endif")));
If_Labels.remove(If_Labels.size() - 1);
}
while
if (word.ClassCodeOf("WHILETK")) {
getNewWhileLabel();
Pcodes.add(new Pcode(PcodeKey.label, While_Labels.get(While_Labels.size() - 1).get("while")));
getWordMove();//while
IndexWhile++;
getWordMove();//(
analyseCond("while");
checkRightParent();
Pcodes.add(new Pcode(PcodeKey.jz, While_Labels.get(While_Labels.size() - 1).get("endwhile")));
Pcodes.add(new Pcode(PcodeKey.label, While_Labels.get(While_Labels.size() - 1).get("whileblock")));
analyseStmt();
IndexWhile--;
Pcodes.add(new Pcode(PcodeKey.jmp, While_Labels.get(While_Labels.size() - 1).get("while")));
Pcodes.add(new Pcode(PcodeKey.label, While_Labels.get(While_Labels.size() - 1).get("endwhile")));
While_Labels.remove(While_Labels.size() - 1);
}//break
else if (word.ClassCodeOf("BREAKTK")) {
getWordMove();//break
if (IndexWhile == 0) {
Error("m", curTokenWord.getLineNum());
}
checkSemicn();
Pcodes.add(new Pcode(PcodeKey.jmp, While_Labels.get(While_Labels.size() - 1).get("endwhile")));
}//continue
else if (word.ClassCodeOf("CONTINUETK")) {
getWordMove();//continue
if (IndexWhile == 0) {
Error("m", curTokenWord.getLineNum());
}
checkSemicn();
Pcodes.add(new Pcode(PcodeKey.jmp, While_Labels.get(While_Labels.size() - 1).get("while")));
}
加减、乘除,比较运算表达式
以比较为例
public void analyseRelExp(ArrayList<TokenWord> exp) {
Expressions exps = divideExp(exp, new ArrayList<>(Arrays.asList("LSS", "LEQ", "GRE", "GEQ")));
int j = 0;
for (ArrayList<TokenWord> tmpExp : exps.getExpressions()) {
analyseAddExp(tmpExp);
if (j > 0 && j <= exps.getExpressions().size()) {
if (exps.getSymbols().get(j - 1).ClassCodeOf("LSS")) {
Pcodes.add(new Pcode(PcodeKey.cmplt));
} else if (exps.getSymbols().get(j - 1).ClassCodeOf("LEQ")) {
Pcodes.add(new Pcode(PcodeKey.cmple));
} else if (exps.getSymbols().get(j - 1).ClassCodeOf("GRE")) {
Pcodes.add(new Pcode(PcodeKey.cmpgt));
} else if (exps.getSymbols().get(j - 1).ClassCodeOf("GEQ")) {
Pcodes.add(new Pcode(PcodeKey.cmpge));
}
}
GrammarString.add("<RelExp>");
if (j < exps.getSymbols().size()) {
GrammarString.add(exps.getSymbols().get(j++).toString());
}
}
}
需要注意的是,由于采用逆波兰表达式,当分析到第二个表达式的时候,其实j已经跳到第二个表达式后面了,所以需要判断的是j-1位置处
如何运行Pcode
Pcode虚拟机是用于运行Pcode命令的虚构机器。 它由一个代码区(pcodes)、一个指令指针(EIP)、一个main函数指针(mainAddress)、一个堆栈(存放各种数值)、存放返回信息的数组、一个变量表var_table,一个函数表func_table和一个标签表label_table组成。
我定义了一个PcodeExecutor类,对应着我的Pcode虚拟机
private int eip = 0;
//mainAddress标记main函数的地址
private int mainAddress;
private Scanner scanner;
private ArrayList<Pcode> pcodes;
private ArrayList<RetInfo> retInfos = new ArrayList<>();
//模拟存放各种数值的栈
private ArrayList<Integer> stack = new ArrayList<>();
private HashMap<String, Variety> varTable = new HashMap<>();
private HashMap<String, Function> funcTable = new HashMap<>();
//label对应的代码行数(eip)
private HashMap<String, Integer> labelTable = new HashMap<>();
初始化
将scanner和pcode代码初始化,同时扫描Pcode代码,将扫描到的标签(名称,位置)加入标签表,函数(名称,function)加入函数表,
public PcodeExecutor(ArrayList<Pcode> pcodes, Scanner sc) {
this.pcodes = pcodes;
this.scanner = sc;
int index = 0;
while (index < pcodes.size()) {
Pcode pcode = pcodes.get(index);
switch (pcode.getKey()) {
case label:
labelTable.put(pcode.getFirstValue().toString(), index);
break;
case func:
funcTable.put(pcode.getFirstValue().toString(), new Function(index, (int) pcode.getSecondValue()));
break;
case mainfunc:
mainAddress = index;
break;
}
index++;
}
}
基本操作
获取变量
如果当前变量表中存在该变量,则直接返回,否则在全局变量中寻找
private Variety getVar(String varName) {
if (varTable.containsKey(varName)) {
return varTable.get(varName);
} else {
//全局变量
return retInfos.get(0).getVarTable().get(varName);
}
}
push、pop
private void push(int value) {
stack.add(value);
}
//弹出并返回
private int pop() {
int value = stack.get(stack.size() - 1);
stack.remove(stack.size() - 1);
return value;
}
获取变量在栈上的绝对地址
注意这里的维数是相对的 for example, to int a[3][2] ,a[0][0] is 0, a[0] is 1, a is 2 a[3][2],SecondDim:2;FirstDim:3
private int getAddress(Variety var, int Dimension) {
int Address = 0;
int n = var.getDimension() - Dimension;
if (n == 0) {
Address = var.getOffset();
}
if (n == 1) {
int i = pop();
if (var.getDimension() == 1) {
Address = var.getOffset() + i;
} else {
Address = var.getOffset() + i * var.getSecondDimNum();
}
}
if (n == 2) {
int i = pop();
int j = pop();
Address = var.getOffset() + j * var.getSecondDimNum() + i;
}
return Address;
}
运行代码
首先定义几个变量
//已经存在的参数数量
int ExistParamsNum = 0;
//调用所需的参数数量
int CallParamsNum = 0;
boolean MainFuncFlag = false;
//函数实参对应的栈上的地址列表
ArrayList<Integer> rparams = new ArrayList<>();
var
产生新的变量,置于stack末尾,放进变量表
case var: {
Variety var = new Variety(stack.size());
varTable.put((String) pcode.getFirstValue(), var);
}
push
//对于数字的话,push进栈里
case push: {
if (pcode.getFirstValue() instanceof Integer) {
push((int) pcode.getFirstValue());
}
}
pop
pop操作:*value1 = value2
在我的定义中,我会在变量赋值以前依次将其在栈中对应的地址以及所赋的值压进栈中
case pop: {
int value = pop();
int address = pop();
stack.set(address, value);
}
计算
Calculation Type
Two operators:
int b = pop();
int a = pop();
push(cal(a,b));
Single operator:
push(cal(pop()));
数组维数
声明变量维数,紧跟着的是维数
case dimarrayvar: {
Variety var = getVar((String) pcode.getFirstValue());
int dimension = (int) pcode.getSecondValue();
var.setDimension(dimension);
if (dimension == 2) {
var.setSecondDimNum(pop());
var.setFirstDimNum(pop());
}
if (dimension == 1) {
var.setFirstDimNum(pop());
}
}
占位符
case defaultvalue: {
Variety var = getVar((String) pcode.getFirstValue());
int dimension = (int) pcode.getSecondValue();
if (dimension == 0) {
push(0);
}
if (dimension == 1) {
for (int i = 0; i < var.getFirstDimNum(); i++) {
push(0);
}
}
if (dimension == 2) {
for (int i = 0; i < var.getFirstDimNum() * var.getSecondDimNum(); i++) {
push(0);
}
}
}
getint
读取int
case getint: {
int value = scanner.nextInt();
push(value);
}
跳转
如果是条件跳转,取出stack中最后一个值判断
函数定义
-
main函数case mainfunc: { MainFuncFlag = true; //retInfos[0] storage 全局变量(varTable) retInfos.add(new RetInfo(pcodes.size(), stack.size() - 1, varTable, 0, 0, 0)); varTable = new HashMap<>(); } -
自定义函数
遇见func定义的话,均先进入到main函数中,等到调用的时候再跳转
case func: { int flag = MainFuncFlag ? 1 : 0; if (flag == 0) { eip = mainAddress - 1; } }
函数调用
总体上来说,就是遇到函数调用->存实参数(值/地址)->存下retInfo,产生新变量表(用于函数),跳转到定义处->遇到形参,依次存入新变量表->遇到ret,进行返回,将原retinfo还原
First, before function call, there will be some parameters to be pushed into the stack. Each will be followed by a rparam command, which memorize the address of the previous variety.
注意:对于传值实参,若是数组具体到某个数(本质是传具体值),对应操作先push各维度,再getvalue,若是具体数值,就是push数值,因此直接rparams.add(stack.size() - 1)。对于传地址参数,则是先push数组名,再getaddress,因此需要将其地址压入
case rparam: {
int dimension = (int) pcode.getSecondValue();
if (dimension == 0) {
//对于非数组的参数,直接将其值压入栈中
//因此其地址是栈顶的地址
rparams.add(stack.size() - 1);
} else {
//对于数组的参数,将其地址压入栈中
rparams.add(stack.get(stack.size() - 1));
}
}
Second, function CALL.
Memorize the eip, stack top address, and information about the function(In fact, they will be pushed into stack too). Then update the varTable and eip. Ready for execute function.
case call: {
Function func = funcTable.get((String) pcode.getFirstValue());
retInfos.add(new RetInfo(eip, stack.size() - 1, varTable, func.getParamsNum(), func.getParamsNum(), ExistParamsNum));
//跳转至函数定义处
eip = func.getOffset();
varTable = new HashMap<>();
CallParamsNum = func.getParamsNum();
ExistParamsNum = 0;
}
Finally, return when it’s RET
Restore eip, varTable from RetInfo, clear the new information pushed when function in the stack.
case ret: {
int type = (int) pcode.getFirstValue();
RetInfo retInfo = retInfos.remove(retInfos.size() - 1);
eip = retInfo.getEip();
varTable = retInfo.getVarTable();
CallParamsNum = retInfo.getCallParamsNum();
ExistParamsNum = retInfo.getNowParamsNum();
if (type == 1) {
//有返回值的话,由于之前将返回值压入栈中,故需要保留栈顶元素
stack.subList(retInfo.getStackPtr() + 1 - retInfo.getParamsNum(), stack.size() - 1).clear();
} else {
stack.subList(retInfo.getStackPtr() + 1 - retInfo.getParamsNum(), stack.size()).clear();
}
}
Additional:
储存完实参,调用函数以后跳转到函数定义的地方
fparam:Firstvalue:Ident_name Secondvalue:Type/Dimension
case fparam: {
//函数现在需要的形参的index
int nowfparamIndex = rparams.size() - CallParamsNum + ExistParamsNum;
int addressOnStack = rparams.get(nowfparamIndex);
Variety fparam = new Variety(addressOnStack);
int dimension = (int) pcode.getSecondValue();
fparam.setDimension(dimension);
//二维数组需要将第二维大小作为参数传入
if (dimension == 2) {
fparam.setSecondDimNum(pop());
}
varTable.put((String) pcode.getFirstValue(), fparam);
ExistParamsNum++;
//如果形参已经全部生成,就清空rparams数组里对应的其形参
if (ExistParamsNum == CallParamsNum) {
rparams.subList(rparams.size() - CallParamsNum, rparams.size()).clear();
}
}
break;
打印输出
print:Firstvalue:String Secondvalue:output num quantity
case print: {
String str = (String) pcode.getFirstValue();
int num = (int) pcode.getSecondValue();
int q = num - 1;
StringBuilder sb = new StringBuilder();
ArrayList<Integer> OutParams = new ArrayList<>();
for (int i = 0; i < num; i++) {
OutParams.add(pop());
}
for (int j = 0; j < str.length(); j++) {
if (j < str.length() - 1) {
if (str.charAt(j) == '%' && str.charAt(j + 1) == 'd') {
sb.append(OutParams.get(q--).toString());
j++;
continue;
}
}
sb.append(str.charAt(j));
}
//除去引号
OutputString.add(sb.substring(1, sb.length() - 1));
}
break;
获取变量的值,地址
Firstvalue:Ident_name Secondvalue:Dimension
case getvalue: {
Variety var = getVar((String) pcode.getFirstValue());
int dimension = (int) pcode.getSecondValue();
int address = getAddress(var, dimension);
push(stack.get(address));
}
break;
//获得变量在栈上的地址,给定变量名和维度
case getaddress: {
Variety var = getVar((String) pcode.getFirstValue());
int dimension = (int) pcode.getSecondValue();
int address = getAddress(var, dimension);
push(address);
}
break;
编码后设计
小细节问题
-
在
GrammarAnalysis中,新增CurLayerId变量,注意和layer区分-
前者为了区分符号表内
变量所处层级,因此不考虑出区块减一,而后者用来构造符号表的HashMap,有并列关系,所以出了区块就要减一 -
两者每次新进入一个区块之后,都会加一
-
但是退出一个区块的时候,前者不会减一,而后者依旧减一
-
public void addSymbol(TokenWord tokenWord, String type, int Dimension, int CurLayerId) { SymbolTables.get(layer).SymbolInsert(type, Dimension, tokenWord, CurLayerId); }
-
Pcode代码对应表
Common Type
| CodeType | Value1 | Value2 | Operation |
|---|---|---|---|
| label | label_name | set a label | |
| var | ident_name | declare a variety | |
| push | ident_name/digit | push(value1) | |
| pop | ident_name | 在pop命令以前push进来的赋值语句右面的式子的值 | *value1 = value2(这个value2指的是在pop命令以前push进来的赋值语句右面的式子的值) |
| jz | label_name | jump if stack top is zero | |
| jnz | label_name | jump if stack top is not zero | |
| jmp | label_name | jump unconditionally | |
| main | main function label | ||
| func | function label | ||
| endfunc | end of function label | ||
| fparam | ident_name | dimension/type | 函数形参parameters |
| ret | return value or not(0:void;1:int) | function return(ret 0无返回值,1有返回值) | |
| call | function name | function call | |
| rparam | ident_name | dimension | 函数实参get parameters ready for function call |
| getint | get a integer and put it into stack top | ||
| string | para num | pop values and print. | |
| dimarrayvar | ident_name | type/dimension | set dimension info for array variety |
| getvalue | ident_name | type/dimension | 对于普通变量,get the variety value |
| getaddress | ident_name | type/dimension | 对于数组,get the variety address |
| defaultvalue | ident_name | type/dimension | push something to hold places |
| exit | exit |
运算比较
| CodeType | Value1 | Value2 | Operation |
|---|---|---|---|
| add | + | ||
| sub | - | ||
| mul | * | ||
| div | / | ||
| mod | % | ||
| cmpeq | == | ||
| cmpne | != | ||
| cmpgt | > | ||
| cmplt | < | ||
| cmpge | >= | ||
| cmple | <= | ||
| and | && | ||
| or | || | ||
| not | ! | ||
| neg | - | ||
| pos | + |
短路求值问题
There are two situations I need to use short circuit calculation :
1. if(a&&b) // a is false
2. if(a||b) // a is true
My method is as follows:
First, when I analyze analyseLOrExp, every analyseLAndExp will be followed by a JNZ, which is used for detect if the cond is true. If it is, jump to the if body label. At the same time, I generated cond label, which is ready for the analyseLAndExp.
private void analyseLOrExp(ArrayList<Word> exp, String from) {
...
for (...) {
...
String label = labelGenerator.getLabel("cond_" + i);
analyseLAndExp(exp1, from, label);
codes.add(new PCode(CodeType.LABEL, label));
if (...) {
codes.add(new PCode(CodeType.OR));
}
if (...) {
if (...) {
codes.add(new PCode(CodeType.JNZ, ifLabels.get(ifLabels.size() - 1).get("if_block")));
}
...
}
...
}
}
In the analyseLAndExp, every analyseEqExp will be followed by a JZ, which is used for detect if the cond is true. If it is not, jump to the cond label I set just now.
private void analyseLAndExp(ArrayList<Word> exp, String from, String label) {
...
for (...) {
...
analyseEqExp(exp1);
if (...) {
codes.add(new PCode(CodeType.AND));
}
if (...) {
if (...) {
codes.add(new PCode(CodeType.JZ, label));
}
...
}
}
}
By these means, short circuit calculation is solved.
七. 代码示例
int y=3;
int b[1][3]={{1,2,3}};
int func(int x[][3])
{
return x[0][2]+y;
}
int func2(int a)
{
int s=a+b;
return a;
}
int main(){
int q=3;
int x=q;
int z;
int y=func(b);
z=func2(3);
printf("%d",3);
return 0;
}
var 0_y
push 3
var 0_b
push 1
push 3
dimarrayvar 0_b, 2
push 1
push 2
push 3
FUNC @func:
push 3
fparam 1_x, 2
push 1_x
push 0
push 2
getvalue 1_x, 0
push 0_y
getvalue 0_y, 0
add
ret 1
endfunc
FUNC @func2:
fparam 2_a, 0
var 2_s
push 2_a
getvalue 2_a, 0
push 0_b
getaddress 0_b, 2
add
push 2_a
getvalue 2_a, 0
ret 1
endfunc
mainfunc main
var 3_q
push 3
var 3_x
push 3_q
getvalue 3_q, 0
var 3_z
defaultvalue 3_z, 0
var 3_y
push 0_b
getaddress 0_b, 2
rparam b, 2
$func
push 3_z
getaddress 3_z, 0
push 3
rparam 3, 0
$func2
pop 3_z
push 3
print "%d"
push 0
ret 1
exit

